Research
|
Analysis of Semi-Supervised Methods for Facial Expression Recognition
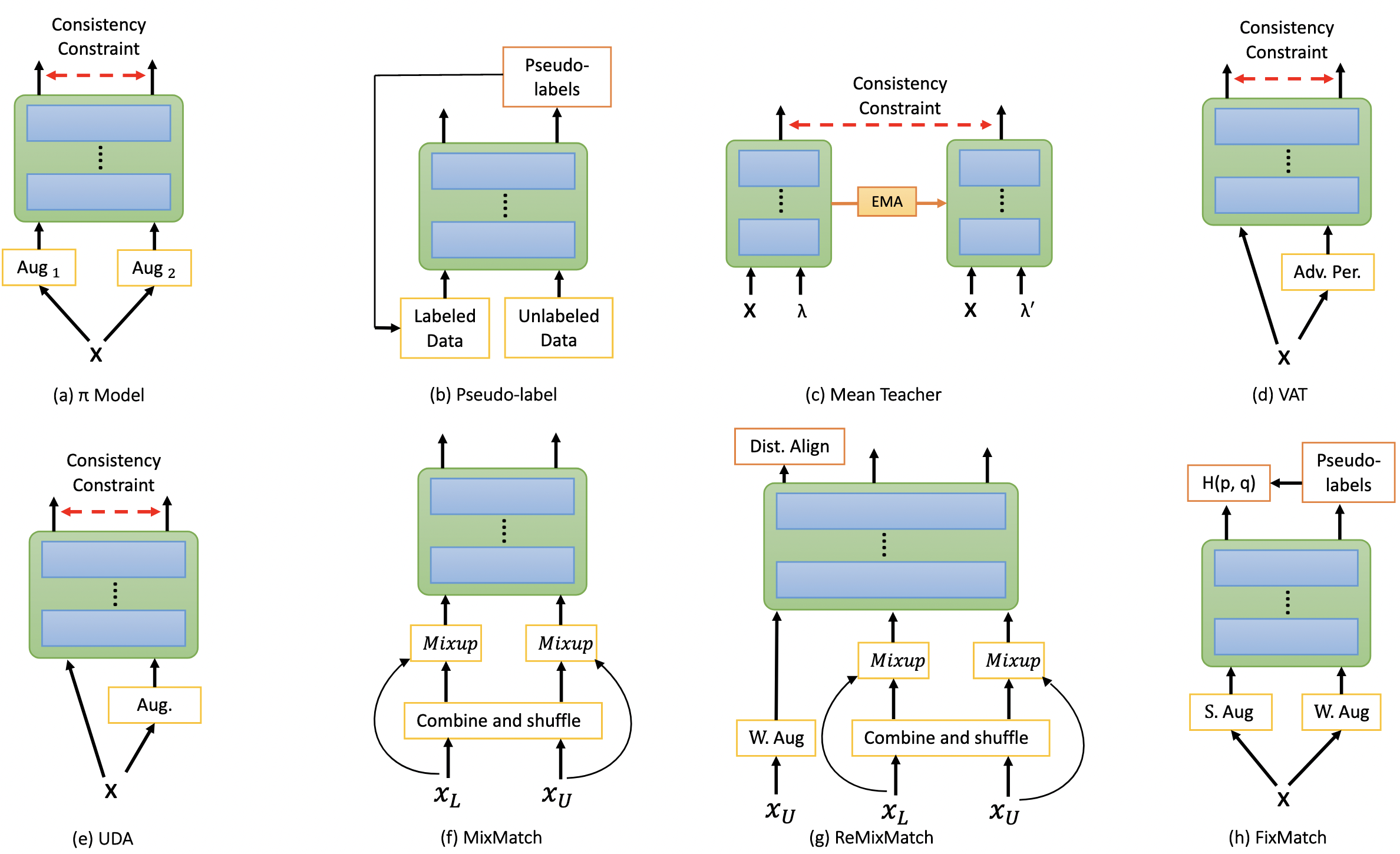
Shuvendu Roy, Ali Etemad IEEE International Conference on Affective Computing and Intelligent Interaction (ACII), 2022 Paper | Project Page | GitHub Training deep neural networks for image recognition often requires large-scale human annotated data. To reduce the reliance of deep neural solutions on labeled data, state-of-the-art semi-supervised methods have been proposed in the literature. Nonetheless, the use of such semi-supervised methods has been quite rare in the field of facial expression recognition (FER). In this paper, we present a comprehensive study on recently proposed state-of-the-art semi-supervised learning methods in the context of FER. We conduct comparative study on eight semi-supervised learning methods, namely Pi-Model, Pseudo-label, Mean-Teacher, VAT, MixMatch, ReMixMatch, UDA, and FixMatch, on three FER datasets (FER13, RAF-DB, and AffectNet), when various amounts of labeled samples are used. We also compare the performance of these methods against fully-supervised training. Our study shows that when training existing semi-supervised methods on as little as 250 labeled samples per class can yield comparable performances to that of fully-supervised methods trained on the full labeled datasets. To facilitate further research in this area, we make our code publicly available at: https://github.com/ShuvenduRoy/SSL_FER. |
|
Self-supervised Contrastive Learning of Multi-view Facial Expressions
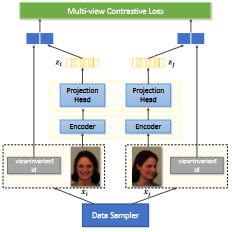
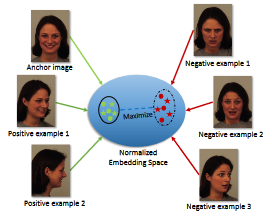
Shuvendu Roy, Ali Etemad ACM International Conference on Multimodal Interaction (ICMI), 2021 Paper | arXiv We propose Contrastive Learning of Multi-view facial Expressions (CL-MEx) to exploit facial images captured simultaneously from different angles towards FER. CL-MEx is a two-step training framework. In the first step, an encoder network is pre-trained with the proposed self-supervised contrastive loss, where it learns to generate view-invariant embeddings for different views of a subject. The model is then fine-tuned with labeled data in a supervised setting. We demonstrate the performance of the proposed method on two multi-view FER datasets, KDEF and DDCF, where state-of-the-art performances are achieved. Further experiments show the robustness of our method in dealing with challenging angles and reduced amounts of labeled data. |
|
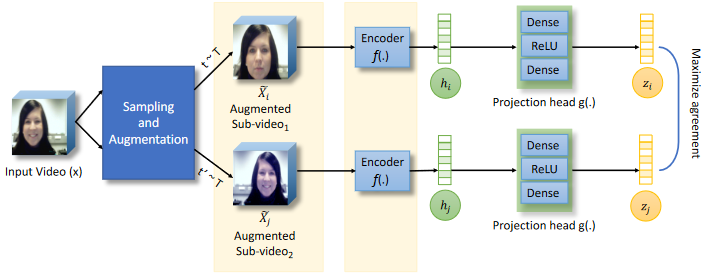
Spatiotemporal Contrastive Learning of Facial Expressions in Videos
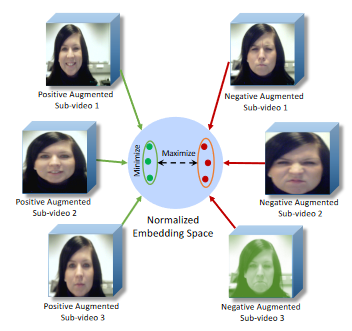
Shuvendu Roy, Ali Etemad IEEE International Conference on Affective Computing and Intelligent Interaction (ACII), 2021 Paper | arXiv We propose a self-supervised contrastive learning approach for facial expression recognition (FER) in videos. We propose a novel temporal sampling-based augmentation scheme to be utilized in addition to standard spatial augmentations used for contrastive learning. Our proposed temporal augmentation scheme randomly picks from one of three temporal sampling techniques: (1) pure random sampling, (2) uniform sampling, and (3) sequential sampling. This is followed by a combination of up to three standard spatial augmentations. We then use a deep R(2+1)D network for FER, which we train in a self-supervised fashion based on the augmentations and subsequently fine-tune. |
|
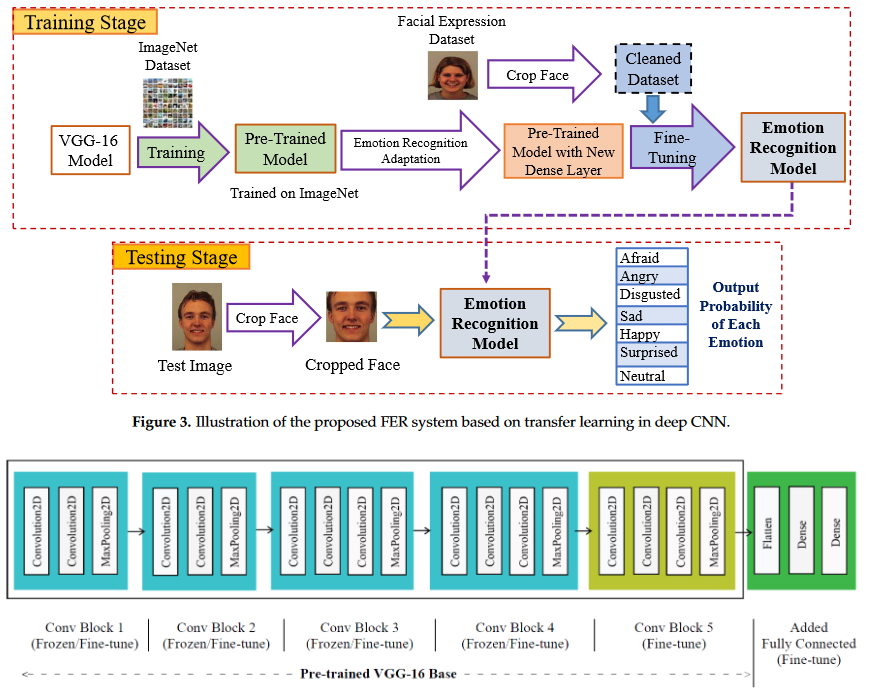
Facial Emotion Recognition Using Transfer Learning in the Deep CNN
MAH Akhand, Shuvendu Roy, Nazmul Siddique, Md Abdus Samad Kamal, Tetsuya Shimamura Electronics 10 (9), 2021 Paper | Undergrad Thesis | Code | Third Party Implementation For developing a highly accurate FER system, this study proposes a very Deep CNN (DCNN) modeling through Transfer Learning (TL) technique where a pre-trained DCNN model is adopted by replacing its dense upper layer(s) compatible with FER, and the model is fine-tuned with facial emotion data. A novel pipeline strategy is introduced, where the training of the dense layer(s) is followed by tuning each of the pre-trained DCNN blocks successively that has led to gradual improvement of the accuracy of FER to a higher level. |